ELK 套件分析Rails日志
当系统访问很频繁,服务器日志增多到一定量时,仅靠 tail -f 已经很难分析出有用信息了。
可能就只能进行一些简单的排除工作,比如根据日志内的时间信息,查找该时间附近有什么特殊访问之类。
即使这样用有时候也会比较麻烦,因为当你的应用服务器增多时,每个服务器都是单独写到本机日志文件内,造成了分析日志的难度。
这个时候就很需要一个工具来收集各个服务器日志来统一处理。
今天说的就是有关于这个问题的解法。
日志收集的工具也有不少 Flume,storm。 今天说的是 ELK stack 这个套件。这个套件由 3 个部分组成:
简单地说: Logstash 用来收集数据;ElasticSearch 存储数据;Kibana 是表现层,Web 接口用来对接用户UI。
ElasticSearch
相信 ElasticSearch 大家可能听说的,是做全文搜索的,跟 Solr 差不多是基于 Lucene 来做的。他有几个特点:
- RESTful Web 接口
- API 数据基于 JSON
- 分布式架构
当然 Solr 现在也可以放到多台服务器上组成集群了,但是 ElasticSearch 从一开始就是这么设计的,这种与生俱来的特性与后天修补出来的体验是否一样,你懂得。
ElasticSearch 在 ELK 套件中处于数据存储的身份,无疑是最核心的。
Logstash
Logstash 可以单独使用,比如把各个服务器的日志收集起来集成到一个日志文件内,这样只要看一个日志文件,就不需要费力到每个服务器查看日志了。
当然结合今天介绍的套件使用无疑是最强大的。
Logstash 作为输入接口,他有很多插件可用,对接文件,对接网络接口,甚至对接 ElasticSearch 作为输入。
比如在我们的例子中,要收集多台日志文件,Logstash 可以开 TCP 端口,各个日志服务器使用 filebeat 代理来检查日志输出,一旦有新的日志输出到文件,filebeat 就会把该内容发送到 Logstash 配置的端口内,这样就完成了日志的收集工作。
Logstash 在收集了日志后,还可以对数据进行 分析,拆解成多个字段,再输出到 ElasticSearch 中,这样就能使用 ElasticSearch 强大的功能对这些字段进行搜索了。
Kibana
Kibana 作为最后的用户 UI 接口,支持了很多分析的功能。比如分析每天的PV情况,一天内访问的高峰与低谷,异常攻击情况,瓶颈的处理等。
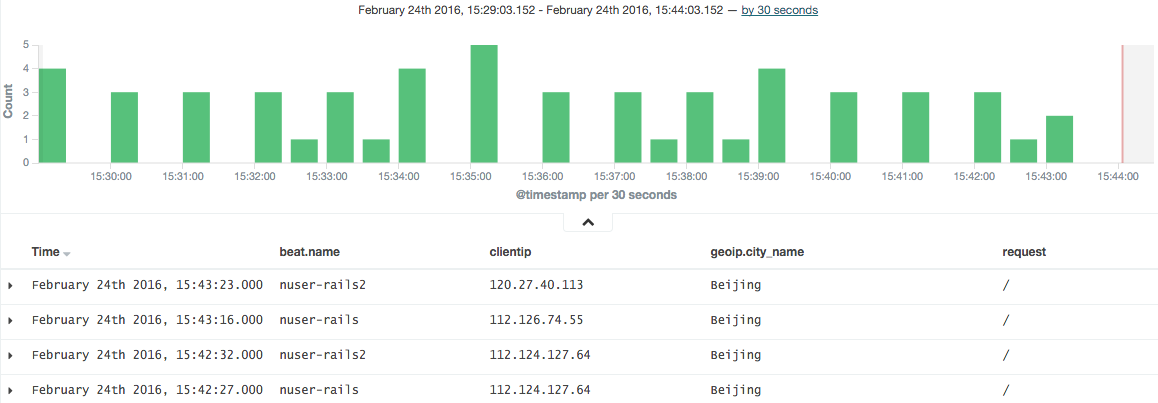
实际应用
下面是配置的 Rails4 日志的分析结构
补充要说的是,时间戳默认是以 Logstash 收到的日志数据的系统时间为每条日志时间戳的,这与时间日志发生的时间并不一致,
需要抽出日志内容里的时间为日志时间戳,这个需要在以下的处理:
1 | data { |
完整的Logstash 配置文件例子